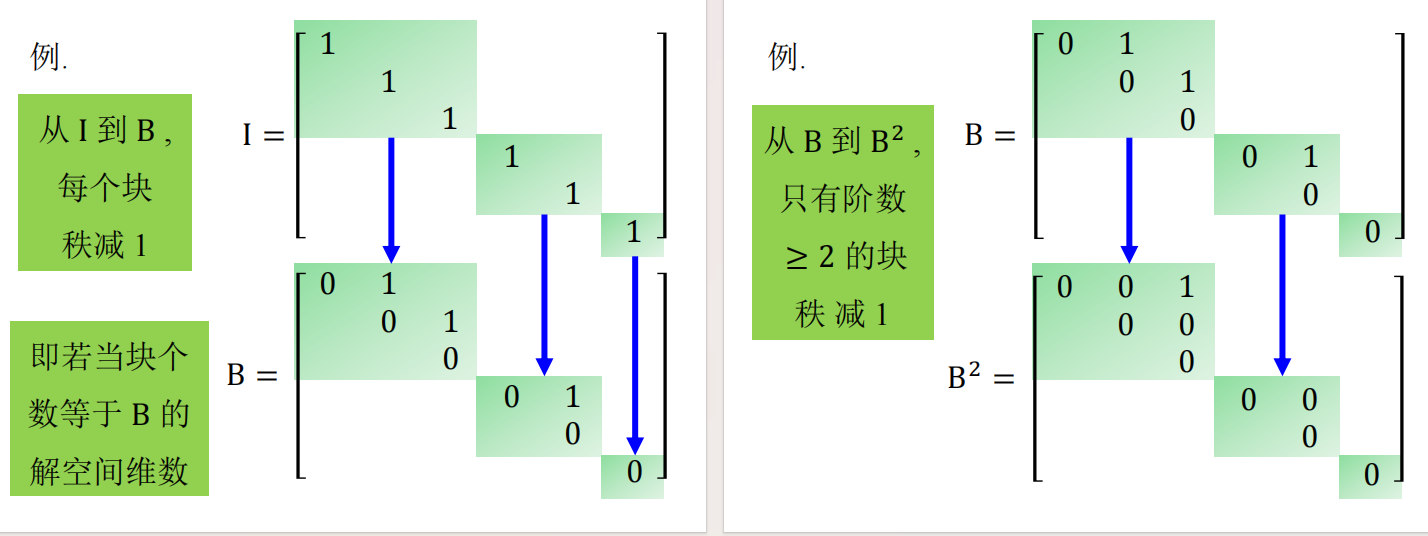
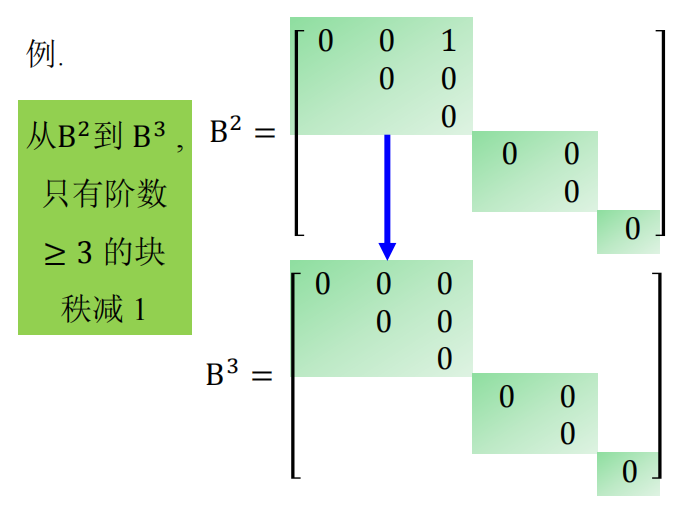
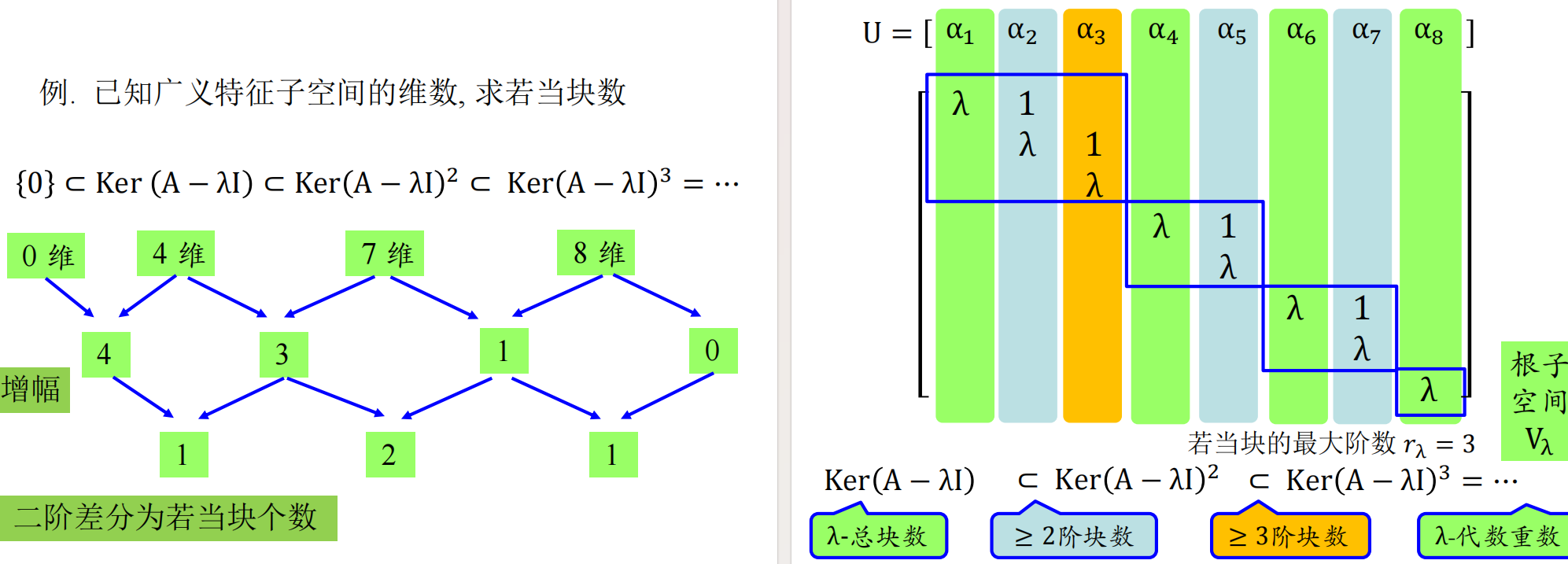
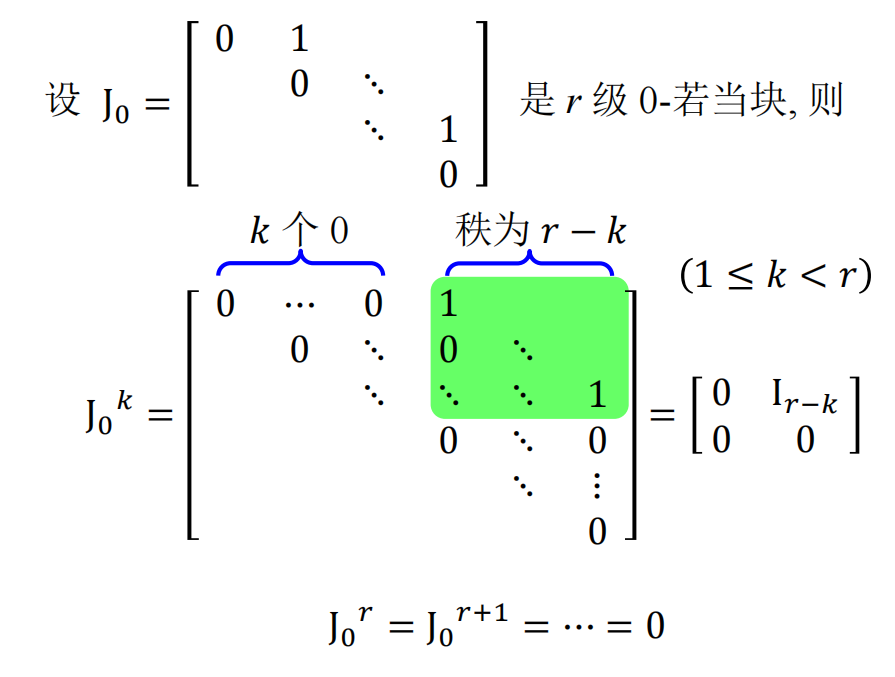
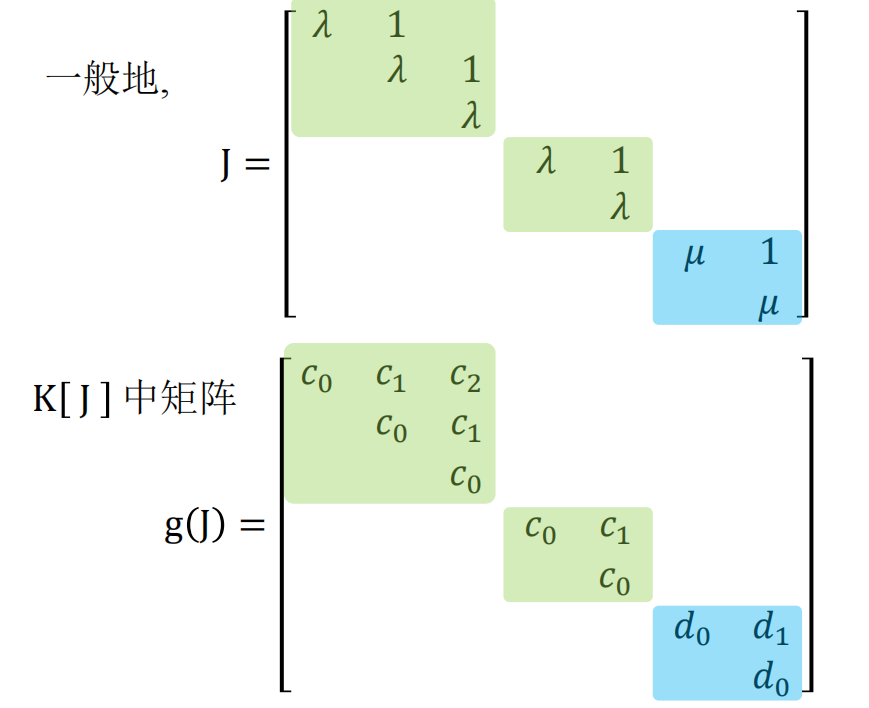
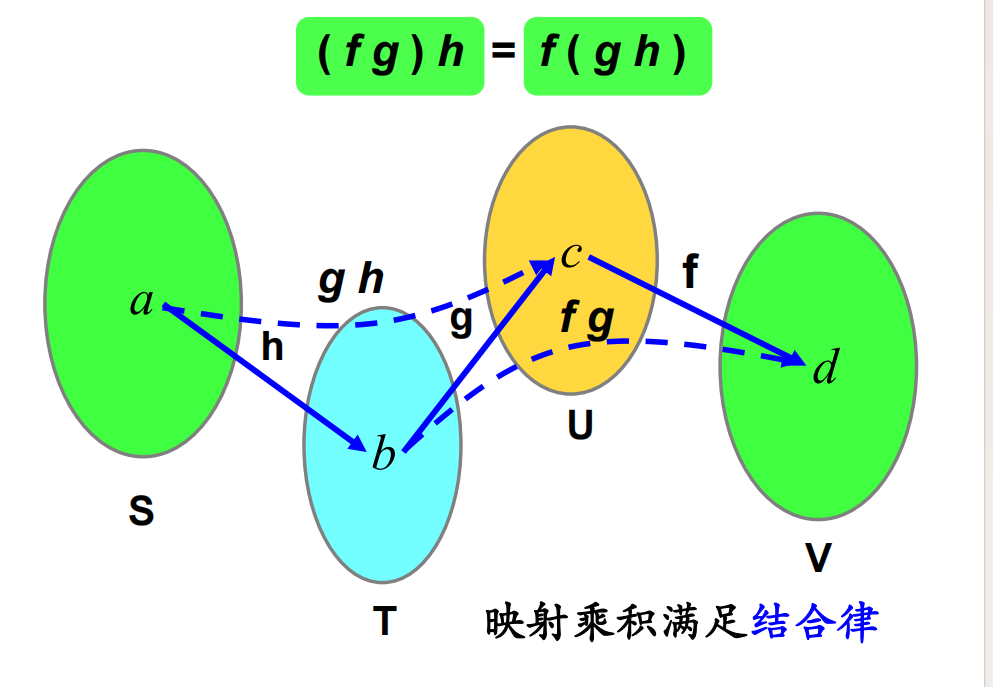
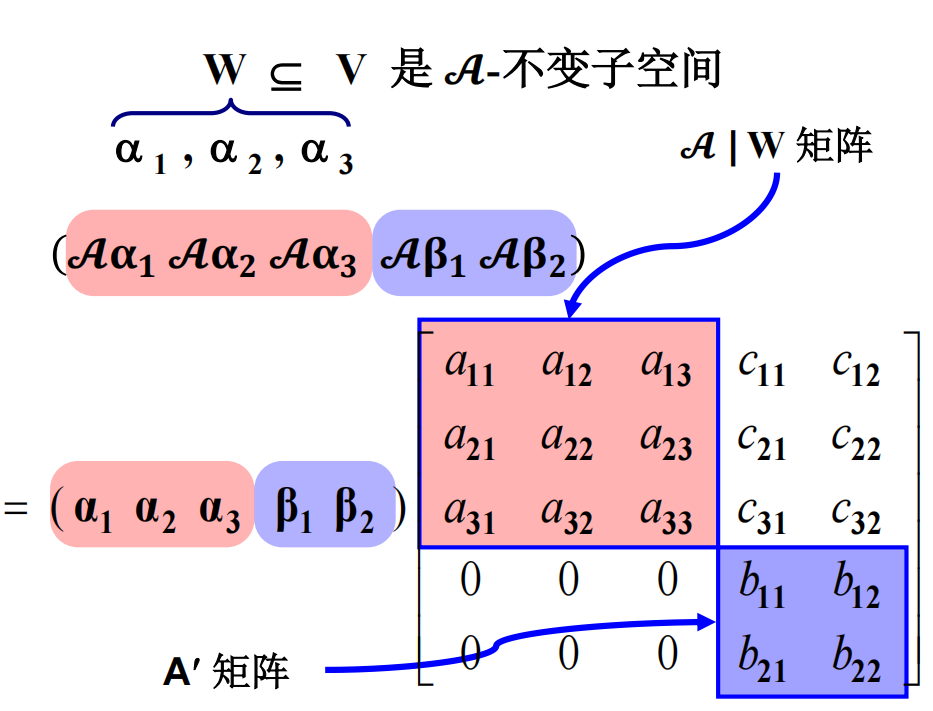
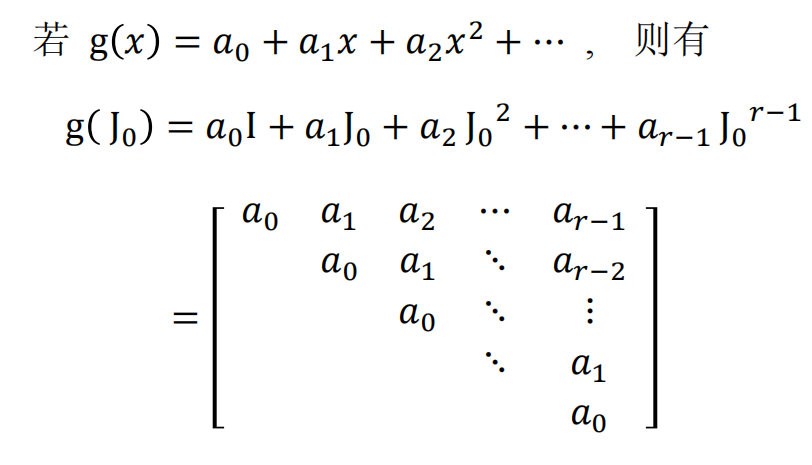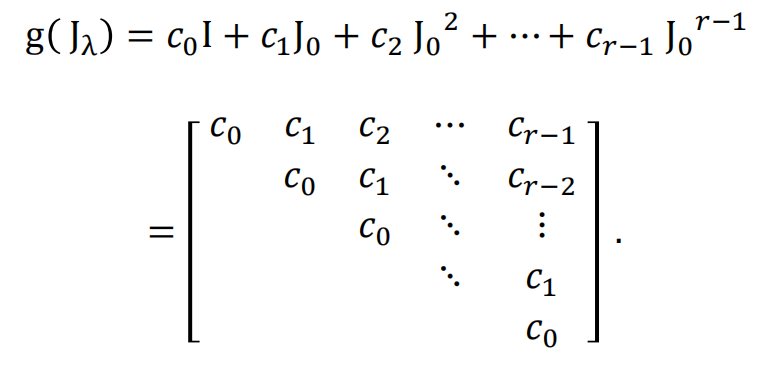我们介绍一种推导计算若当标准型与有理标准型的新方法, 它是模的理论衍化而来的 $\lambda$-矩阵法的改进.在 $\lambda$-矩阵方法的发展历史中, 字符 $\lambda$承载了过多的历史使命: 它既当做多项式的变元, 又表示矩阵的特征值, 在早期甚至还用来代表线性变换. 故在下面的讨论中,$\lambda$ 只用来表示矩阵的特征值,多项式的变量统一用字符 x 表示。
鉴于并不很熟悉,将更多以教材似的铺陈为主,而非有很明确的主线串一起。
$x$-矩阵及其运算
设 $K$ 是一个域,$x$是一个字符. 若一个矩阵的元素都是$K[x]$里的多项式,则称该矩阵为$x$-矩阵. 为了与普通数字矩阵相区分,我们下面用 $A(x), B(x), \cdots$表示$x$-矩阵,$x$-向量.
像普通矩阵一样,$x$-矩阵也可以作加法,乘法以及与 $K[x]$ 中多项式的“数乘”,也有行列式,代数余子式和可逆的概念.
例:若 $A \in M_n(K)$,则 $xI_n - A$是$x$-矩阵,称为 $A$的特征矩阵;其行列式$|xI_n - A|$就是$A$ 的 特征多项式

既然分量是多项式,我们自然考虑对应的数论关系,对一个多项式 $d(x)$,如果两个x-向量每个分量的差都是$d(x)$的倍式,就说他们模$d(x)$ 同余。
同时我们可以如上把一个x-向量拆成若干个向量以x幂次为系数的线性组合,例如 $L(x)$是一个x-向量,对任意的$\lambda$ 显然可以唯一表示成
$$
L(x)\equiv \sum_{i=1}^{r} \alpha_i(x-\lambda)^{i-1} \pmod{(x-\lambda)^r}
$$
那么想让右侧为 $0$ ,也只有
$$
\forall i,\alpha_i=0
$$
我们会发现这和上个笔记中提到的 $g(\lambda)$被$(x-\lambda)^r$整除的等价条件非常像,同时注意到乘上一个$(x-\lambda)$会让每个向量后移一个,例如$\alpha_0$ 就没了,$\alpha_1$对应原来$\alpha_2$对应的$(x-\lambda)^2$所以这应该就对应了一个循环子空间,或者说对应了一个$Jordan$ 块。
引理
设 $A \in M_n(K)$,$\lambda \in K$是$A$的一个特征值。设存在一个$n$维$x$-列向量 $L(x)$,满足 $L(\lambda) \neq 0$ 且:
$$
(A - xI) L(x) \equiv 0 \pmod{(x - \lambda)^r}
$$
那么如上方写成
$$
L(x) = \alpha_1 + \alpha_2(x - \lambda) + \cdots + \alpha_r(x - \lambda)^{r-1} \pmod{(x - \lambda)^r}
$$
其中,系数向量 $\alpha_i \in K^n$。
那么
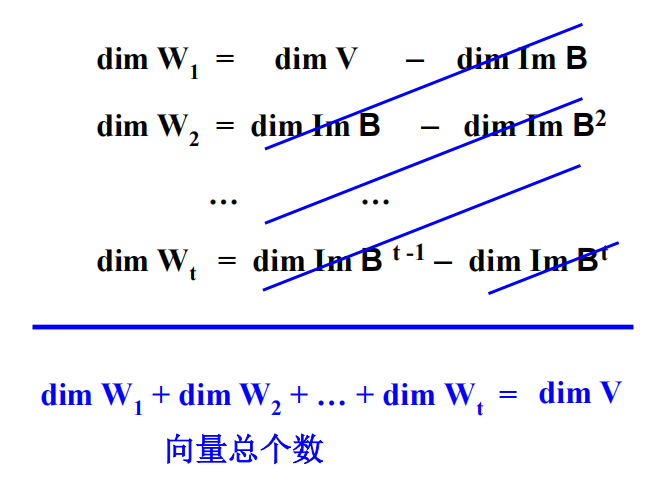
生成的空间:记 $V = \langle \alpha_r, \alpha_{r-1}, \dots, \alpha_1 \rangle$,则 $V$是一个由$\alpha_r$ 生成的 $(A - \lambda I)$-强循环子空间。
循环基(Jordan 链):这组向量满足以下递推关系:
$$
\begin{cases} \alpha_{r-1} = (A - \lambda I)\alpha_r \\ \alpha_{r-2} = (A - \lambda I)\alpha_{r-1} = (A - \lambda I)^2\alpha_r \\ \vdots \\ \alpha_1 = (A - \lambda I)^{r-1}\alpha_r \end{cases}
$$
- 重要性质:尾项 $\alpha_1 = L(\lambda)$恰好是$A$对应于特征值$\lambda$的一个特征向量(因为$(A-\lambda I)\alpha_1 = 0$),且根据前提 $\alpha_1 \neq 0$。
证明
首先,我们先凑出 $(x-\lambda)$ :
$$
(A-x I)L(x)=(A-\lambda I-(x-\lambda)I)L(x)\equiv 0\pmod{(x-\lambda)^r}
$$
写开 $L(x)$ 也就是
$$
((A - \lambda I) - (x - \lambda)I) \begin{bmatrix} \alpha_1 & \alpha_2 & \cdots & \alpha_r \end{bmatrix} \begin{bmatrix} 1 \\ x - \lambda \\ \vdots \\ (x - \lambda)^{r-1} \end{bmatrix}\equiv 0 \pmod{(x - \lambda)^r}
$$
用分配律拆开
$$
((A - \lambda I) \begin{bmatrix} \alpha_1 & \alpha_2 & \cdots & \alpha_r \end{bmatrix} - \begin{bmatrix} 0 & \alpha_1 & \cdots & \alpha_{r-1} \end{bmatrix} ) \begin{bmatrix} 1 \\ x - \lambda \\ \vdots \\ (x - \lambda)^{r-1} \end{bmatrix}\equiv 0 \pmod{(x - \lambda)^r}
$$
第二项实际上也就是一个 $J_0$ 的形式
$$
\begin{bmatrix} 0 & \alpha_1 & \cdots & \alpha_{r-1} \end{bmatrix}= \begin{bmatrix} \alpha_1 & \alpha_2 & \cdots & \alpha_r \end{bmatrix} \begin{bmatrix} 0 & 1 & & \\ & 0 & \ddots & \\ & & \ddots & 1 \\ & & & 0 \end{bmatrix} .
$$
这对任意 $x$ 都成立,所以只有
$$
(A - \lambda I) \begin{bmatrix} \alpha_1 & \alpha_2 & \cdots & \alpha_{r-1} & \alpha_r \end{bmatrix} = \begin{bmatrix} \alpha_1 & \alpha_2 & \cdots & \alpha_r \end{bmatrix} \begin{bmatrix} 0 & 1 & & \\ & 0 & \ddots & \\ & & \ddots & 1 \\ & & & 0 \end{bmatrix} .
$$
故有:
$$
\alpha_{r-1} = (A - \lambda I) \alpha_r ,
$$
$$
\alpha_{r-2} = (A - \lambda I) \alpha_{r-1} = (A - \lambda I)^2 \alpha_r ,
$$
$$
\cdots \quad \cdots
$$
$$
\mathbf{\alpha_1} = (A - \lambda I) \alpha_2 = (A - \lambda I)^{r-1} \alpha_r \neq 0 ,
$$
以及
$$
(A - \lambda I) \alpha_1 = (A - \lambda I)^r \alpha_r = 0 .
$$
直接长出了一条循环子空间的链。
逆
设 $A(x)$是$n$级$x$-矩阵. 若存在 $n$级$x$-矩阵 $B(x)$, 使得
$$
A(x)B(x) = B(x)A(x) = I_n ,
$$
则称 $x$-矩阵 $A(x)$可逆. 满足以上条件的$B(x)$由$A(x)$唯一确定, 称为$A(x)$的逆, 记为$A(x)^{-1}$.
例如
$$
\begin{bmatrix} 1 & 0 & 0 \\ 3 & 1 & 0 \\ x+1 & 1 & -1 \end{bmatrix} \begin{bmatrix} 1 & 0 & 0 \\ -3 & 1 & 0 \\ x-2 & 1 & -1 \end{bmatrix} = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix}
$$
引理: $n$级$x$-矩阵 $A(x)$可逆当且仅当$|A(x)|$是$K$ 中非零的数.
证: 若有 $x$-矩阵 $B(x)$, 使得 $A(x)B(x) = I_n$.
两边取行列式, 得 $|A(x)||B(x)| = 1$.
因为 $|A(x)|, |B(x)| \in K[x]$, 由它们乘积为 1 可以推出 $|A(x)|, |B(x)|$ 必须是零次多项式, 即非零常数.
反之, 若 $|A(x)| = d$是域$K$ 中非零的数.
记 $A(x)^$为$A(x)$的伴随矩阵, 则$\frac{1}{d}A(x)^$也是$x$-矩阵, 且满足
$$
A(x) \frac{1}{|A(x)|} A(x)^* = \frac{1}{|A(x)|} A(x)^* A(x) = I_n .
$$
故 $x$-矩阵 $A(x)$可逆, 且$A(x)^{-1} = \frac{1}{d} A(x)^*$.
由此也可以有个简单的推论,$A(x)$可逆那么随便带入一个$x=k$ ,矩阵当然还是可逆。
初等因子与不变因子
初等变换
不难想到,应该也有类似的初等行列变换,但多项式有所不同。最核心的区别在于:“除法”受限了。- 在 $x$-矩阵中,如果你给某行乘以 $x$,其逆操作将是“除以 $x$”。但 $1/x$不是多项式(不属于$K[x]$)。第二类变换只能乘以非零常数(即 $K[x]$ 中的可逆元),否则它就不是初等变换,会改变矩阵的本质属性(如阶数和秩)。
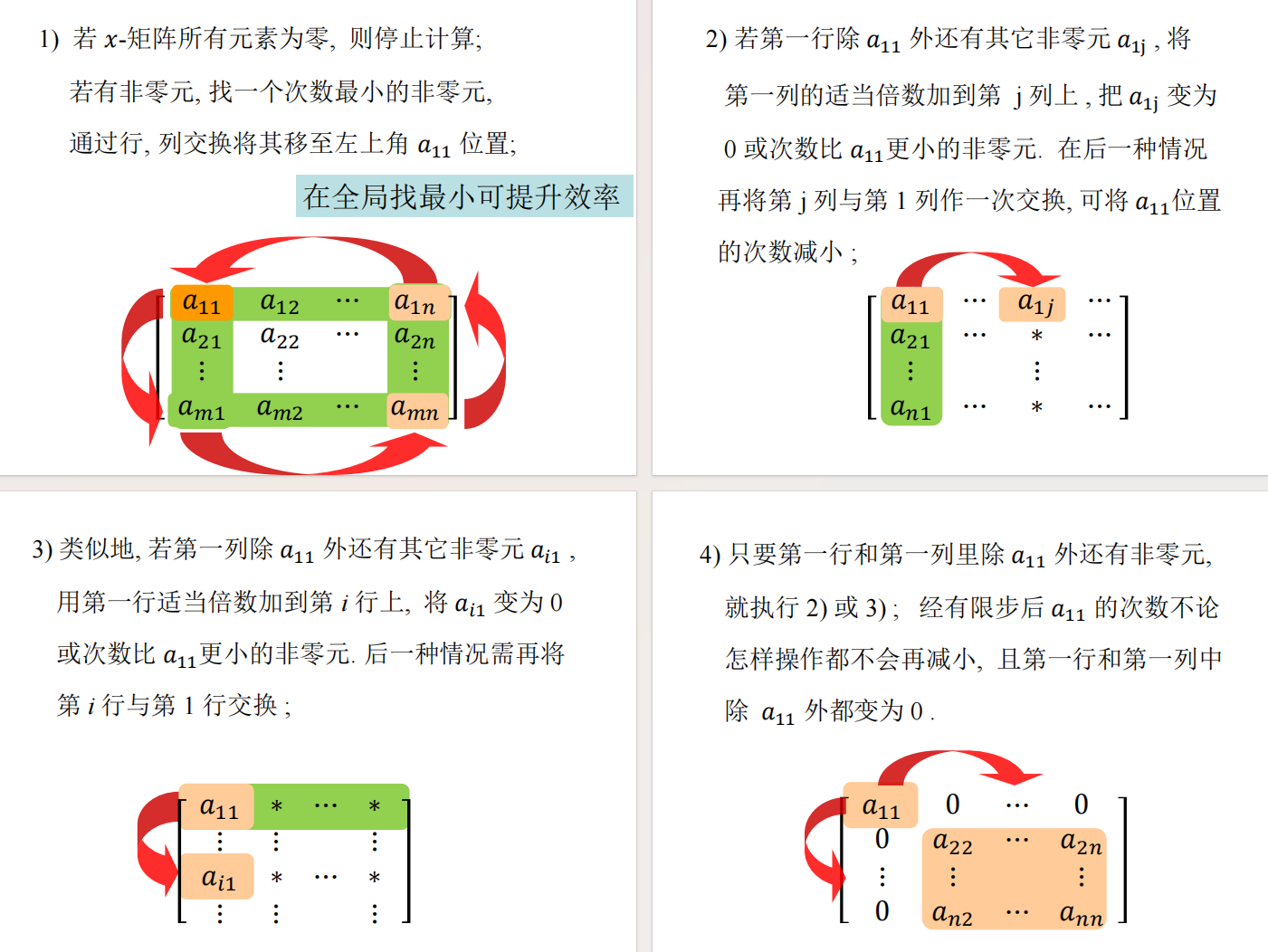

想到上面的结论,如果我们模掉初等因子,是不是可以找到其对应的一个 Jordan 块。
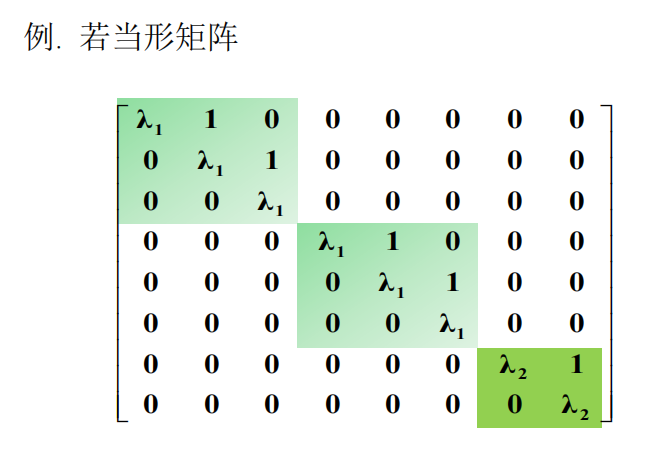
若当(Jordan)标准型的存在性
若 $A \in M_n(K)$的特征多项式在域$K$上能分解成一次因式的乘积,则存在可逆矩阵$U \in M_n(K)$,使得 $U^{-1}AU$ 是若当形矩阵。
证明过程
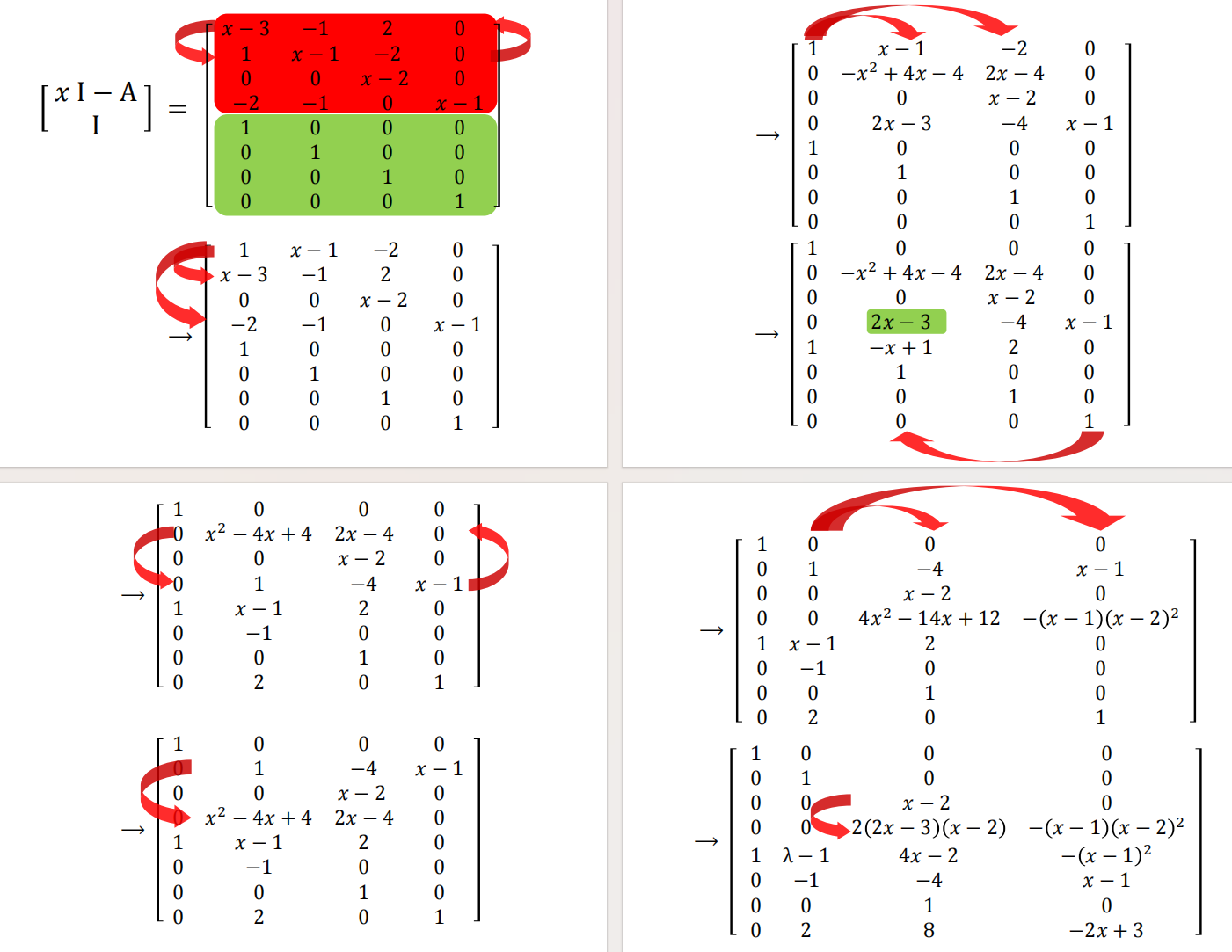
由上,对 $A \in M_n(K)$,总存在可逆的 $x$-矩阵 $P(x), Q(x)$,使得:
$$
(xI - A)Q(x) = P(x)^{-1} \begin{bmatrix} c_1(x) & & \\ & \ddots & \\ & & c_n(x) \end{bmatrix} \quad (1)
$$
设 $(x - \lambda)^r$是$A$的来自$c_i(x)$的一个初等因子。记$Q(x)$的第$i$列为$Q_i(x)$。比较 (1) 式第 $i$ 列得:
$$
(xI - A)Q_i(x) \equiv 0 \pmod{(x - \lambda)^r} \quad (2)
$$
将 $Q_i(x)$的分量展开成$x - \lambda$ 的多项式,将其写成:
$$
Q_i(x) \equiv \alpha_1 + (x - \lambda)\alpha_2 + \cdots + (x - \lambda)^{r-1}\alpha_r \pmod{(x - \lambda)^r} \quad (3)
$$
这里 $\alpha_1, \dots, \alpha_r$是$K^n$中的列向量。注意两侧带入$x=\lambda$可知尾项$\alpha_1$是可逆数字矩阵$Q(\lambda)$的第$i$列$Q_i(\lambda)$,故 $\alpha_1 \neq 0$。
对以上 (2), (3) 式应用引理,我们发现:
$$
V_{i,\lambda} = \langle \alpha_r, \alpha_{r-1}, \dots, \alpha_1 \rangle \subseteq \text{Ker}(A - \lambda I)^r
$$
是 $A - \lambda I$的一个由$\alpha_r$生成的$r$维强循环子空间,且$\alpha_1 = Q_i(\lambda)$是$V_{i,\lambda}$ 一组循环基的尾项。
现考察同属特征值 $\lambda$但来自不同对角元$c_i(x)$ ($1 \le i \le n$) 的初等因子:$(x - \lambda)^{r_1}, (x - \lambda)^{r_2}, \dots$。它们给出的子空间 $V_{i,\lambda}$都是$(A - \lambda I)$-强循环子空间。这些空间循环基的尾项来自可逆矩阵 $Q(\lambda)$的不同列$Q_i(\lambda)$,故这些尾项线性无关,所以当 $\lambda$固定时,子空间$V_{i,\lambda}$ ($1 \le i \le n$) 之间是直和,我们记此直和为 $V_\lambda$,即 $V_\lambda = \bigoplus_{1 \le i \le n} V_{i,\lambda}$(只取非零的 $V_{i,\lambda}$)。
注意 $V_\lambda \subseteq \text{Ker}(A - \lambda I)^{r_\lambda}$,这里 $r_\lambda$表示属于特征值$\lambda$ 的所有初等因子的最高次数。
当 $\lambda$取遍$A$的不同特征值时,广义特征子空间$\text{Ker}(A - \lambda I)^{r_\lambda}$之间都是直和关系,故其子空间$V_\lambda$之间也为直和关系。再结合$V_\lambda$的定义知$A$的全部初等因子给出的子空间$V_{i,\lambda}$ ($\forall i, \lambda$) 之和是直和。
最后说明这个直和就是 $K^n$每个子空间$V_{i,\lambda}$的维数等于其对应初等因子的次数。由于$A$的特征多项式在域$K$上能分解成一次因式的乘积,故$A$的全体初等因子的次数和等于$n$。比较直和的维数,得:
$$
\bigoplus_{\lambda, i} V_{i,\lambda} = \bigoplus_\lambda V_\lambda = K^n
$$
(同上,只取非零的 $V_{i,\lambda}$ 作直和)。
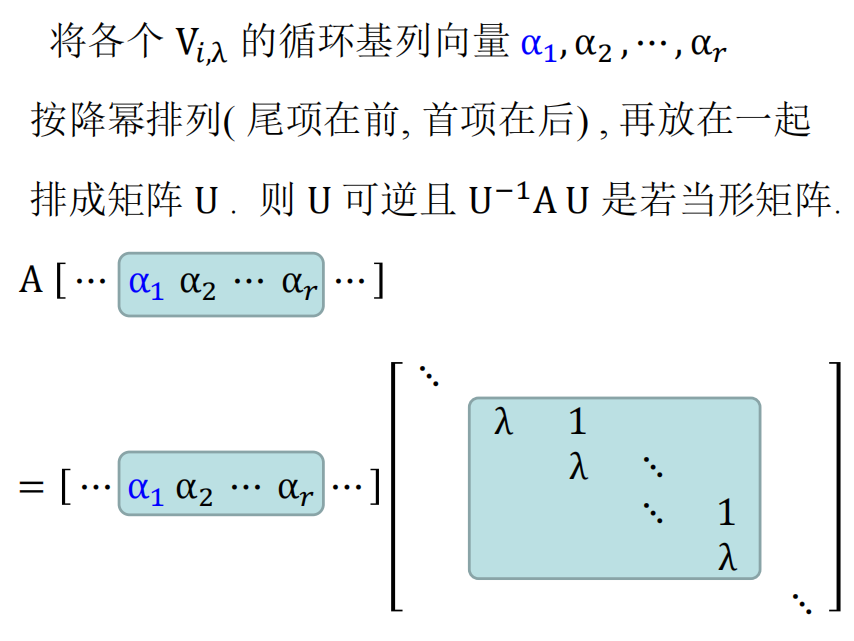
这就完成了证明,还顺便给出了一种构造。
注:比较各子空间
$$
V_\lambda = \bigoplus_{1 \le i \le n} V_{i,\lambda} \subseteq \text{Ker}(A - \lambda I)^{r_\lambda} \quad \text{及}
$$
$$
K^n = \bigoplus_\lambda \bigoplus_{1 \le i \le n} V_{i,\lambda} \subseteq \bigoplus_\lambda \text{Ker}(A - \lambda I)^{r_\lambda} \subseteq K^n
$$
的维数,我们发现:
$$
V_\lambda = \bigoplus_{1 \le i \le n} V_{i,\lambda} = \text{Ker}(A - \lambda I)^{r_\lambda}
$$
(取非零的 $V_{i,\lambda}$作直和)就是$A$的根空间,其维数等于属于$\lambda$的所有初等因子的次数和,即特征值$\lambda$的代数重数。当$\lambda$取遍$A$ 的特征值时, 我们又得到主分解定理
$$
\bigoplus_\lambda V_\lambda = \bigoplus_\lambda \text{Ker}(A - \lambda I)^{r_\lambda} = K^n .
$$
这样就得到了另一条路线的结论。
示例

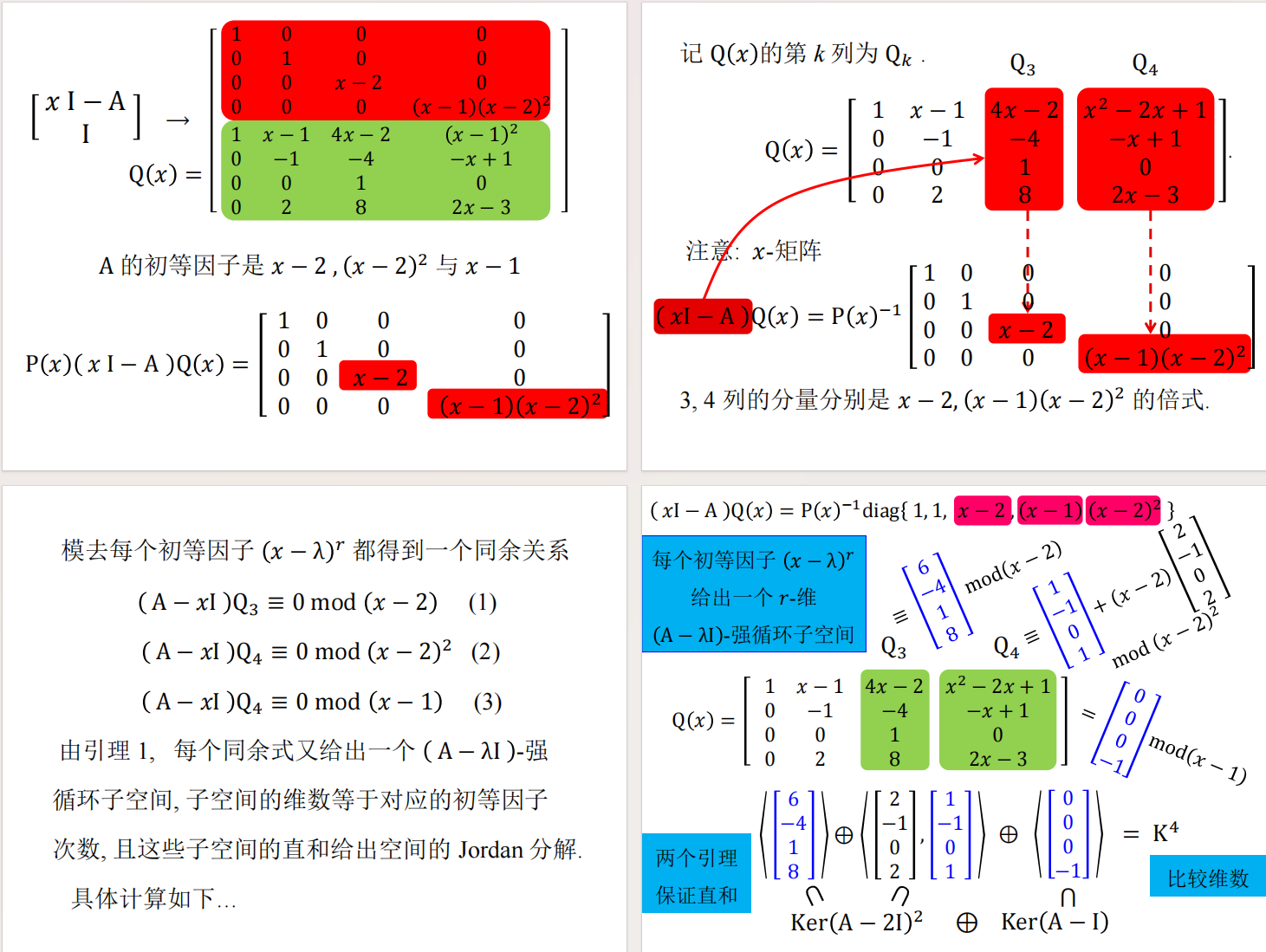
蓝色的向量就是 $Q$对应的列直接令$x=\lambda$ 得到的尾项,据此我们可以写出完整的链。
我们可以看到,每个初等因子 $(x-\lambda)^r$都给出了一个$r$ 维的强循环子空间,这和若当块一一对应。所以求出初等因子,我们也就得到了若当块的全部,形状加上特征值。回忆起在上次笔记中提到,相似等价于若当标准型相同,于是也就得到等价于初等因子相同。
不变因子与有理标准型
如果 A , B ∈ $M_n(K)$ 的特征多项式不能在域 K上分解成一次因式的积, 或因式分解很难计算,怎么判断 A , B 是否相似, 如何求过渡矩阵 ?
友阵
先做一点铺垫,从我们熟知的循环子空间开始,由于维度限制,会得到
$$
\beta,A\beta,...,A^{v-1}\beta
$$
线性无关但是
$$
\beta,...,A^v\beta
$$
线性相关,那么也就得到一个零化多项式
$$
\beta+A\beta+...+A^v\beta=0
$$
记 $d(x)=x^v+b_1x^{v-1}+…+b_v$也就是$A$ 的零化多项式,而且是最小多项式。$A$ 在这个空间的限制映射,我们也知道,形式优美
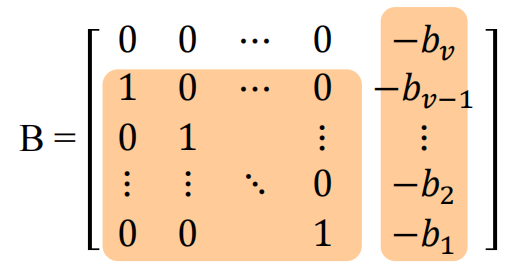
而且他的特征多项式也就是 $d(x)$。这就称$B$是$d(x)$ 的友阵。
之前我们把 $L(x)$展开成$(x-\lambda)$的幂次再去作用,但是变化未必可以分解成如此漂亮的一次因式,现在我们考虑在模$d(x)$ 的情况下直接作用。
引理
设 $A \in M_n(K)$,$d(x)$为$v \ge 1$次首一多项式。又设有列向量$\beta_1, \dots, \beta_v \in K^n$,使得
$$
(A - xI)(\beta_1 + x\beta_2 + \dots + x^{v-1}\beta_v) \equiv 0 \pmod{d(x)}.
$$
则
$$
\langle \beta_1, \beta_2, \dots, \beta_v \rangle = \langle \beta_v, A\beta_v, \dots, A^{v-1}\beta_v \rangle
$$
且 $d(A)\beta_v = 0$。
注: 光凭以上条件还不足以推出 $\beta_1, \dots, \beta_v$ 线性无关。
证明
设 $d(x) = x^v + b_1x^{v-1} + \dots + b_v \in K[x]$,并记 $X = [1, x, x^2, \dots, x^{v-1}]^T$,则
$$
(A - xI)(\beta_1 + x\beta_2 + \dots + x^{v-1}\beta_v)
$$
如同初等因子那,我们也是分配律拆开
$$
= A [\beta_1, \beta_2, \dots, \beta_v] X - (x\beta_1 + x^2\beta_2 + \dots + x^v\beta_v)
$$
在模 $d$下,把$x^v$降次,并把除了$\beta_v$ 之外的挪进前面就出现一个移位的形式
$$
\equiv (A [\beta_1, \beta_2, \dots, \beta_v] - [0, \beta_1, \dots, \beta_{v-1}]) X + (b_1x^{v-1} + \dots + b_v)\beta_v
$$
$$
\equiv 0 \pmod{d(x)}
$$
比较最后一个等式向量分量里 $x$ 方幂的系数,得:
$$
A [\beta_1, \beta_2, \dots, \beta_v] = [0, \beta_1, \dots, \beta_{v-1}] - [b_v\beta_v, b_{v-1}\beta_v, \dots, b_1\beta_v]
$$
$$
= [\beta_1, \beta_2, \dots, \beta_v] \begin{bmatrix} 0 & 1 & & \\ & 0 & \ddots & \\ & & \ddots & 1 \\ -b_v & -b_{v-1} & \dots & -b_1 \end{bmatrix}.
$$
由于并非强循环子空间,还出现了一排系数,但这正是友阵(转置)的形式
也可以一项一项写出,即:
$$
\begin{cases} A\beta_v = \beta_{v-1} - b_1\beta_v \\ A\beta_{v-1} = \beta_{v-2} - b_2\beta_v \\ \dots \\ A\beta_2 = \beta_1 - b_{v-1}\beta_v \\ A\beta_1 = -b_v\beta_v \end{cases}
$$
反推
$$
\beta_{v-1} = A\beta_v + b_1\beta_v = (A + b_1I)\beta_v,
$$
$$
\beta_{v-2} = A\beta_{v-1} + b_2\beta_v = (A^2 + b_1A + b_2I)\beta_v,
$$
$$
\dots, \dots
$$
$$
\beta_1 = A\beta_2 + b_{v-1}\beta_v = (A^{v-1} + b_1A^{v-2} + \dots + b_{v-1}I)\beta_v
$$
及
$$
A\beta_1 + b_v\beta_v = d(A)\beta_v = 0.
$$
用矩阵表示,有
$$
[\beta_1 \ \beta_2 \ \cdots \ \beta_{v-1} \ \beta_v]
= [\beta_v \ A\beta_v \ A^2\beta_v \ \cdots \ A^{v-1}\beta_v] \begin{bmatrix} b_{v-1} & b_{v-2} & \cdots & b_1 & 1 \ b_{v-2} & b_{v-3} & \cdots & 1 & 0 \ \vdots & \vdots & \ddots & \vdots & \vdots \ b_1 & 1 & \cdots & \vdots & 0 \ 1 & 0 & \dots & 0 & 0 \end{bmatrix}.
$$
故
$$
\langle \beta_1, \beta_2, \dots, \beta_v \rangle = \langle \beta_v, A\beta_v, \dots, A^{v-1}\beta_v \rangle.
$$
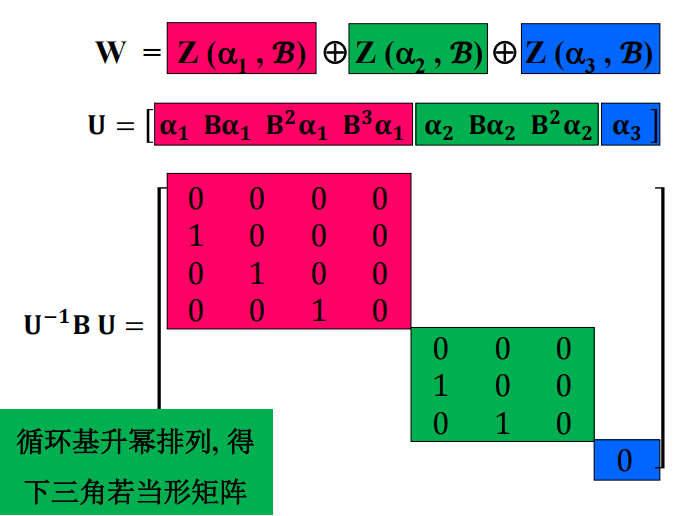
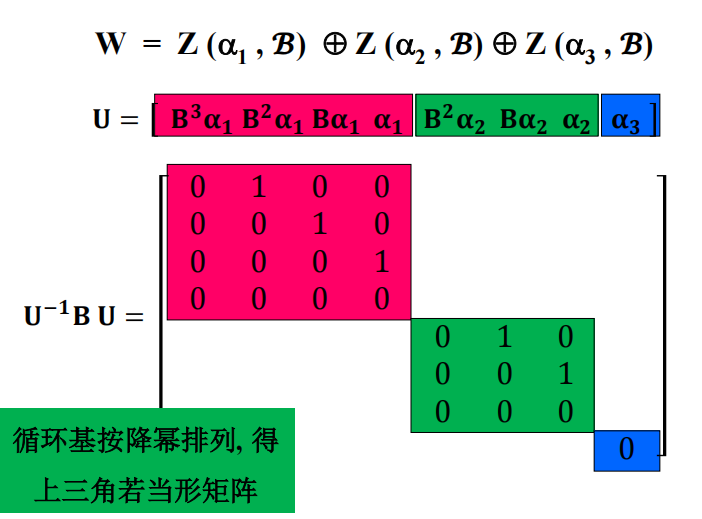
就是说,这样一组 $\beta$ 对应了一条链。
方阵与其转置相似
利用上面的讨论,我们有
$$
A [\beta_1 \ \beta_2 \ \cdots \ \beta_v] = [\beta_1 \ \beta_2 \ \cdots \ \beta_v] \begin{bmatrix} 0 & 1 & & \\ & 0 & \ddots & \\ & & \ddots & 1 \\ -b_v & -b_{v-1} & \cdots & -b_1 \end{bmatrix}
$$
以及
$$
A [\beta_v \ A\beta_v \ \cdots \ A^{v-1}\beta_v] = [\beta_v \ A\beta_v \ \cdots \ A^{v-1}\beta_v] \begin{bmatrix} & & & -b_v \\ 1 & & & -b_{v-1} \\ & \ddots & & \vdots \\ & & 1 & -b_1 \end{bmatrix}
$$
利用
$$
[\beta_1 \ \beta_2 \ \cdots \ \beta_{v-1} \ \beta_v]
= [\beta_v \ A\beta_v \ A^2\beta_v \ \cdots \ A^{v-1}\beta_v] \begin{bmatrix} b_{v-1} & b_{v-2} & \cdots & b_1 & 1 \ b_{v-2} & b_{v-3} & \cdots & 1 & 0 \ \vdots & \vdots & \ddots & \vdots & \vdots \ b_1 & 1 & \cdots & \vdots & 0 \ 1 & 0 & \dots & 0 & 0 \end{bmatrix}
$$
$$
=[\beta_v \ A\beta_v \ A^2\beta_v \ \cdots \ A^{v-1}\beta_v]U
$$
代换就得到
$$
A [\beta_v \ A\beta_v \ A^2\beta_v \ \cdots \ A^{v-1}\beta_v]U = [\beta_v \ A\beta_v \ A^2\beta_v \ \cdots \ A^{v-1}\beta_v]U \begin{bmatrix} 0 & 1 & & \\ & 0 & \ddots & \\ & & \ddots & 1 \\ -b_v & -b_{v-1} & \cdots & -b_1 \end{bmatrix}
$$
显然 $U$ 可逆,那么
$$
A [\beta_v \ A\beta_v \ A^2\beta_v \ \cdots \ A^{v-1}\beta_v] = [\beta_v \ A\beta_v \ A^2\beta_v \ \cdots \ A^{v-1}\beta_v]U \begin{bmatrix} 0 & 1 & & \\ & 0 & \ddots & \\ & & \ddots & 1 \\ -b_v & -b_{v-1} & \cdots & -b_1 \end{bmatrix}U^{-1}
$$
那么就发现
$$
U \begin{bmatrix} 0 & 1 & & \\ & 0 & \ddots & \\ & & \ddots & 1 \\ -b_v & -b_{v-1} & \cdots & -b_1 \end{bmatrix}U^{-1}=\begin{bmatrix} & & & -b_v \\ 1 & & & -b_{v-1} \\ & \ddots & & \vdots \\ & & 1 & -b_1 \end{bmatrix}
$$
其中
$$
U=\begin{bmatrix} b_{v-1} & b_{v-2} & \cdots & b_1 & 1 \\ b_{v-2} & b_{v-3} & \cdots & 1 & 0 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ b_1 & 1 & \cdots & \vdots & 0 \\ 1 & 0 & \dots & 0 & 0 \end{bmatrix}
$$
实际上我们也就是做了换基。
我们仔细观察会发现,这两个 Frobenius 矩阵互为转置而相似,那么一般的方阵会和他的转置相似吗?
如果可以这样分解一个方阵,那只要挨个套上面的结论就好了:
$$
Q^{-1} A Q = F = \begin{pmatrix} C_{d_1} & & \\ & \ddots & \\ & & C_{d_k} \end{pmatrix}
$$
其中,每个对角块 $C_{d_i}$ 是首一多项式(Monic polynomial)$d_i(x)$ 的友阵(Companion Matrix)。
对于每一个友阵块 $C_{d_i}$,已知存在对称可逆矩阵 $U_i$使得$U_i C_{d_i} U_i^{-1} = C_{d_i}^T$。我们可以构造一个分块对角矩阵 $P$:
$$
P = \begin{pmatrix} U_1 & & \\ & \ddots & \\ & & U_k \end{pmatrix}
$$
由于每个 $U_i$均可逆,则$P$ 显然可逆。对其进行相似变换:
$$
\begin{aligned} P F P^{-1} &= \begin{pmatrix} U_1 C_{d_1} U_1^{-1} & & \\ & \ddots & \\ & & U_k C_{d_k} U_k^{-1} \end{pmatrix} \\ &= \begin{pmatrix} C_{d_1}^T & & \\ & \ddots & \\ & & C_{d_k}^T \end{pmatrix} \\ &= F^T \end{aligned}
$$
由此证明了标准型 $F$与其转置$F^T$ 相似。
利用 $A = Q F Q^{-1}$,对两端取转置可得:
$$
A^T = (Q^{-1})^T F^T Q^T
$$
将 $F^T = P F P^{-1}$以及$F = Q^{-1} A Q$ 代入上式进行展开:
$$
\begin{aligned} A^T &= (Q^{-1})^T (P F P^{-1}) Q^T \\ &= (Q^{-1})^T P (Q^{-1} A Q) P^{-1} Q^T \\ &= \left( (Q^{-1})^T P Q^{-1} \right) A \left( Q P^{-1} Q^T \right) \end{aligned}
$$
令 $R = (Q^{-1})^T P Q^{-1}$,易证其逆矩阵为 $R^{-1} = Q P^{-1} Q^T$。
上述等式可简写为:
$$
A^T = R A R^{-1}
$$
这说明 $A$相似于$A^T$。该结论在复数域或任何代数封闭域上均成立。
那接下来的问题是,能不能那么分解一个方阵,实际上,这样的分解被称为有理标准型,也确实可以这么干。
有理标准型
若对角分块矩阵 $B = \begin{bmatrix} B_1 & & \ & \ddots & \ & & B_s \end{bmatrix}$的对角块$B_i$ $(1 \le i \le s)$都是某些首一多项式$d_i(x)$的友阵,且这些多项式满足$d_1(x) \mid d_2(x) \mid \cdots \mid d_s(x)$,则称上述矩阵 $B$ 为有理标准形矩阵。
定理:
每个矩阵都相似于唯一的一个有理标准形矩阵。
不变因子
这时我们需要溯源到最开始提到的 x-矩阵的初等变换,如果我们严格按照步骤(4*),就会得到所谓Smith 标准型。
若 $A \in M_n(K)$,则存在可逆的 $x$-矩阵 $P(x), Q(x)$,使得
$$
P(x)(xI - A)Q(x) = \text{Smith 标准型} = \begin{bmatrix} 1 & & & & \\ & \ddots & & & \\ & & d_1(x) & & \\ & & & \ddots & \\ & & & & d_s(x) \end{bmatrix}
$$
这里 $d_i(x)$是次数$\ge 1$ 的首一多项式,满足
$$
d_1(x) \mid d_2(x) \mid \cdots \mid d_s(x) .
$$
我们称 $d_1(x), \cdots, d_s(x)$为$A$ 的不变因子(组)。
初等因子与不变因子
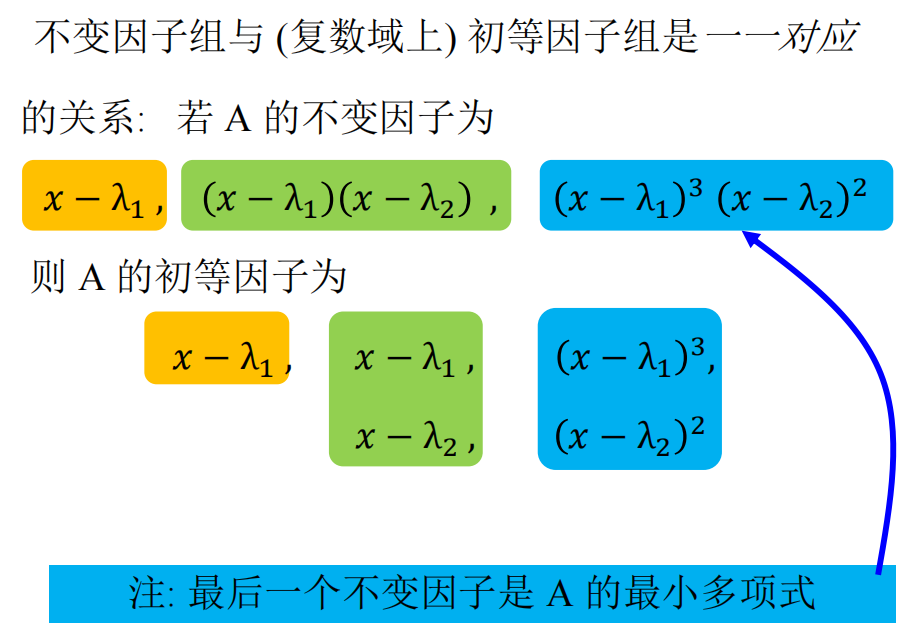
同时,也注意到,初等因子可以重复。
将 $A$的不变因子$d_1(x), \cdots, d_s(x)$在$\mathbb{C}$上因式分解中出现的一次因式的方幂一个一个写下来(相同的需重复记录),就得到$A$ 的全部初等因子。
反之,将 $A$的属于同一特征值的初等因子都写在同一行上,每一行上的初等因子按升幂排列,并按尾项上下对齐(不足的可用$1$补上),再将同一列上的初等因子上下相乘,就变回$A$的不变因子组$d_1(x), \cdots, d_s(x)$。
不变因子不随扩域改变
矩阵 $A \in M_n(K)$ 的不变因子组
$$
d_1(x), \cdots, d_s(x) \in K[x]
$$
由 $A$(的相似等价类)唯一确定,且不依赖于 $K$ 的扩张。
证: 假设 $A$还有另一组不变因子$c_1(x), \cdots, c_t(x)$。由以上不变因子组与 $\mathbb{C}$ 上初等因子组的一一对应关系,$A$在$\mathbb{C}$ 上将有两组不同的初等因子。但是根据之前所述,$A$的初等因子组(因与$A$的若当块绑定)被$A$ 的相似类唯一确定,由此导出矛盾!
不变因子给出空间分解
设 $d_1(x), \cdots, d_s(x)$是$A \in M_n(K)$的不变因子,则存在$\gamma_1, \cdots, \gamma_s \in K^n$,使得
$$
Z(\gamma_1, A) \oplus \cdots \oplus Z(\gamma_s, A) = K^n,
$$
且 $A$在$\gamma_i$处的最小多项式为$d_i(x), \forall 1 \le i \le s$。
这里 $Z(\gamma_i, A)$是由$\gamma_i$ 生成的 $A$-循环子空间。










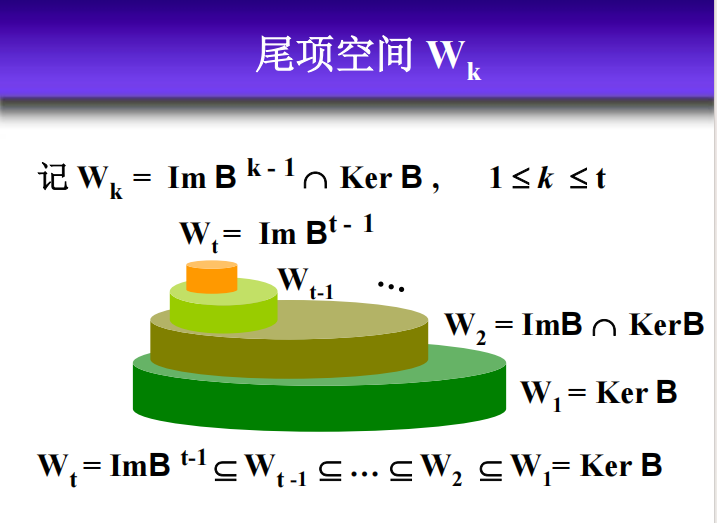

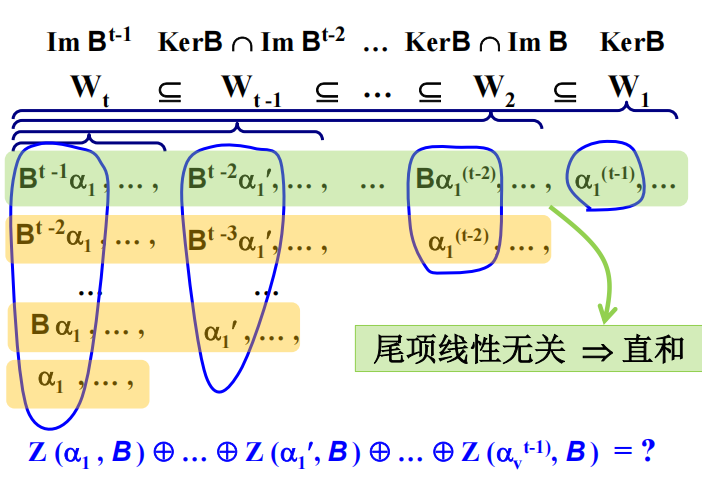 我们需要确定这些直和在一起是否填满了整个 $V$。
我们需要确定这些直和在一起是否填满了整个 $V$。